|
Vincent J. van Heuven, Loulou Edelman, Renée
van Bezooijen, |
||||
|
The pronunciation of /Ei/ by male and female speakers of avant-garde Dutch |
||||
|
In de last decade a new variety of Modern Dutch has emerged, which
was first noted and commented on by the dialectologist Reker in
1993 in a press release by Radio-Noord (for details see Stroop 1998:
13, 107). Taking a cue from Reker's observation, the emerging variety
has been closely monitored by Stroop, who christened it Polder Dutch.
The variety was elegantly described and placed in a wider sociolinguistic
perspective in a popular-scientific brochure by Stroop (1998). More
recently the variety got an entire website devoted to it (www.hum.uva.nl/poldernederlands),
with very thorough documentation - both in Dutch and in English
- on the phenomenon. |
||||
| 1.1. The phonetics of the sound change
The new variety differs from the Standard language only in its phonetics. Stroop presents the change as a chain shift, whereby the tense high mid vowels /e:, 2:, o:/, which have slight diphthongization in the standard language, are somewhat lowered and more noticeably diphthongized. The high mid vowels push the low mid diphthongs /Ei, 9y, Au/ to a more open position. As a result the onset of the low mid diphthongs assumes a position very close to open /a/, so that the three diphthongs are no longer clearly differentiated in their onsets. However, the end points of the diphthongs - which may possibly be lowered as well - still differentiate adequately between the front unrounded /Ei/, the front rounded /9y/, and the back rounded /Au/. It remains unclear from the descriptions provided whether the degree of diphthongization is affected by the sound change. If it is only the onset of the diphthongs that is more open, and the end point remains stable, then the strength of diphthongization (the size of the diphthong trajectory) should have increased. However, if the onset and the endpoint have been lowered together, then the strength of diphthongization should have remained the same. Interestingly, Stroop (1998) transcribes the new variant of the diphthong /Ei/ as aai, which trigraph is the conventional orthographic representation of the long open vowel /a:/ followed by a consonant /j/, as in haai /ha:j/ 'shark' or maait /ma:jt/ 'mows'. The rhymes of these words are appreciably (ca. 50 to 90 ms) longer than their counterparts in hei /hEi/ 'heather' and meid /mEit/ 'maid'1. Also, the vowel in haai and maait remains stationary for a relatively long time, and then abruptly glides off toward /i/, whilst the vowel quality in hei and meid changes from the beginning onwards ('t Hart and Collier 1983; Peeters 1991; Nooteboom and Cohen 1976, Rietveld and van Heuven 2001). Stroop claims that the lowering of /Ei/ reflects a natural tendency.
In fact, low mid diphthongs are rare in the world's languages. Cognates
of Dutch /Ei/ in the neighbouring languages English and German are
fully open diphthongs, e.g., English wine /wain/, German
wein /wain/. The Dutch mid open diphthongs, especially /Ei/
and /{y/ are notoriously difficult for foreign learners of the language.
The fully open alternative would be easier to produce on the strength
of the argument that the speaker just has to open his mouth as wide
as he can to get the vowel right, whilst more intricate articulatory
control would be required for the low-mid variety. If it is true
that the more open variety of /ei/ would also have a larger change
in vowel quality from onset of offset, there is the added advantage
that the diphthongal nature of the vowel would stand out more clearly,
reducing potential perceptual confusion with tense /e:/, which is
also slightly diphthongal, (Nooteboom and Cohen 1976, Rietveld and
van Heuven 2001).
The first aim of this study is to clarify the phonetics of the
sound change in so far as it relates to the pronunciation of the
diphthong /Ei/. Moreover, rather than using the traditional impressionistic
phonetic approach, i.e. listening and transcription, we wish to
settle the issue using acoustic measures of greater mouth opening
and/or stronger diphthongization and lengthening. |
||||
|
2. Experimental approach There is agreement among experimental phoneticians and sociolinguists
that vowel quality, and change of vowel quality in diphthongs, can
be quantified with adequate precision and validity by measuring
the centre frequencies of the lower resonances in the acoustic signal.
Specifically the centre frequency of the lowest resonance of the
vocal tract, called first formant frequency or F1, corresponds closely
to the articulatory and/or perceptual dimension of vowel height
(high vs. low vowels, or close vs. open vowels). For an average
male voice, the F1 values would range between 200 Hertz (Hz) for
a high vowel /i/ to some 800 Hz for a low vowel /a/. The second
formant frequency (or F2) reflects the place of maximal constriction
during the production of the vowel, i.e., the front vs. back dimension,
such that the F2 values range from roughly 2200 Hz for front /i/
down to some 800 Hz for back /u/. |
||||
|
3. Method 3.1 Materials 1. vowels must occur in content words Note that these criteria were applied to the orthographic transcripts
of the recordings. No auditory (let alone acoustic) analysis was
attempted before the vowel tokens were selected - on purely textual
grounds. |
||||
|
4. Results In order to give the reader a feel of the type of data that we
are dealing with, we will begin by presenting a few overviews of
vowel data for individual speakers. Figure 1 represents the acoustic
vowel space for one male and one female speaker, whose vowel tokens
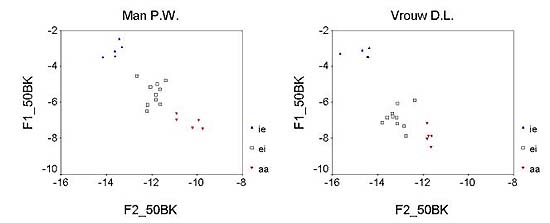
are dispersed in a perfectly regular fashion. The male and the female vowel spaces have been plotted in the same coordinate system so as to facilitate cross-sex comparison. Observe that vowel height ranges between 2 and 8 Bark for the male speaker and between 3 and 9 for the female. Similarly, the front-back values range between 10 and 14 Bark for the male as opposed to 12 and 16 Bark for the female. This is a direct consequence of the cross-sex difference in the size of the oral and pharyngeal cavities. Still, by virtue of the Bark transformation, equal distances across the male and the female vowel spaces are perceptually the same. The data typically show that the reference point vowel tokens are tightly clustered in the left-hand top corner for /i/ and the open-central area for /a/. There is more variability for the target diphthong /Ei/ for both speakers, possibly indicating within-speaker instability for this diphthong. Also, visual inspection reveals that the cloud of /Ei/ onsets for the male speaker finds itself roughly halfway between the /i/ and /a/ clusters. For the female speaker, however, the cloud of /Ei/ onsets seems to have dropped to a relatively lower position between the /i/ and /a/ reference clusters, leaving a wide gap between the /i/ and /Ei/ onset clusters. More problematic cases arise in figure 2, where two more female speakers have been plotted as in figure 1. 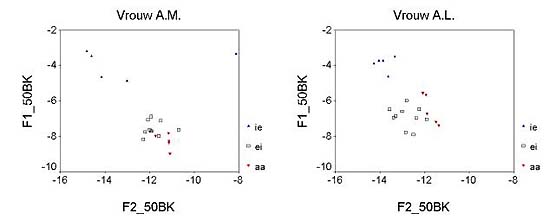
Figure 2. Acoustic vowel diagrams for two more female speakers (further see figure 1). Figure 2 illustrates two problems. Female speaker A.M.'s /i/ tokens (left-hand panel) are far from tightly clustered; in fact, one token seems completely off target, which, incidentally, is not a measurement error but due to extreme rounding and centralization of this /i/ token (which sounds more like /y/). Such occurrences of off-target realizations vowel tokens cannot be avoided, and should not be avoided, when strictly applying the textual selection criteria for inclusion of tokens in the dataset. A similar problem manifests itself in the /a/ reference tokens of female speaker A.L. (right-hand panel). Although we would expect the female /a/ tokens to have F1 values around 9 Bark - as we did indeed find for the female speakers D.L. (figure 1) and A.M. (figure 2 left) - A.L.'s /a/ tokens never extend below 8 Bark. This, again, is probably the result of rather severe centralization of the /a/ tokens, probably due to fast, colloquial speech. In view of the susceptibility of the reference point vowels to reduction (centralization) it seems unwise to adopt the centroid (center of gravity) of the /i/ and /a/ clusters as the reference values when defining the speaker-individual vowel height dimension. Rather we decided to select the single most extreme (i.e. front-most) token within the speaker's /i/ cluster as the high-front endpoint of the dimension, and the most extreme (i.e. most open) /a/ token as the other endpoint. Consequently, the speaker's /i/ token with the highest F2 value and the /a/ token with the highest F1 value were adopted as the extremes of the speaker-individual vowel height dimension. This procedure allows us to express vowel height speaker-individually as a relative measure. The spectral distance between the extreme /i/ token and the extreme /a/ token is set at 100%, such that /i/ has 100% vowel height and /a/ 0%. When some /Ei/ onset finds itself exactly midway between the extreme /i/ and /a/ tokens, its relative height will come out as 50%. This measure is implemented by computing (a) the euclidian distance between the reference endpoints, (b) the euclidian distance between the /Ei/ onset and the /a/ reference value, and (c) the percentage of b relative to a. The smaller the percentage c, the lower the relative starting point of the diphthong. By the same reasoning we define a relative spectral change measure so as to express the speaker-individual degree of diphthongization for the /Ei/ tokens. First we compute the euclidian distance in the Bark-transformed F1 by F2 plane between onset (formant measurements at the 25% temporal point) and offset (measurements at the 75% point) and then take this distance as a percentage of the total distance between extreme /i/ and /a/ of the speaker. A relative glide measure of 25% would then indicate that the /Ei/ glide extends over one quarter of the entire front edge of the speaker's vowel diagram. These speaker-normalized measures of (relative) vowel height of the /Ei/ onset and of the magnitude of the diphthongization are shown in figures 3 and 4, respectively. In these figures the values have been plotted separately for the male and female speakers, such that the speakers are ordered from left to right in ascending order of conservatism in both figures. [note: figures will be redrawn so as to conform to this description; axes will be relabeled in English] It is obvious from figure 3 that the female speakers, on the whole, have lower /Ei/ onsets than the males. There is one man and one woman with an extremely open /Ei/ onset of 20% vowel height. It seems that the change from [Ei] to [ai] has been completed for these two speakers. At the conservative end of the scale, there is one woman with a higher (i.e. more conservative) /Ei/ onset than the most conservative of the male speakers. For the 2 × 14 speakers remaining speakers the women consistently lead in the change from [Ei] to [ai]. The effect of sex is significant by a paired t-test, t(15) = 5.46 (p < .001, one-tail). Figure 4 reveals the same state of affairs with respect to the (normalized) magnitude of the spectral change in the diphthongs. Clearly, the women generally have a larger difference between onset and offset of the diphthongs than the men, t(15) = 2.93 (p = .005, one-tail). Figures 3 and 4 together indicate that the phonetics of the sound change in progress are best characterized as a combined lowering and magnification of the low-mid diphthong: the onset changes from low-mid to fully low but the offset remains more or less stationary, such that a larger spectral distance has to be covered between onset to offset, which would perceptually enhance the diphthongal nature of the vowel. 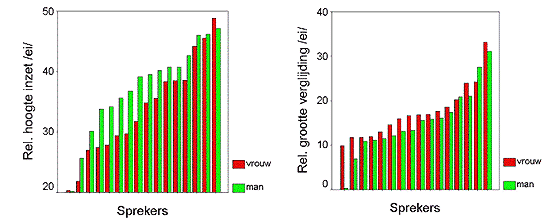
Figure 5 plots the relationship between onset lowering and magnitude of spectral change in the /Ei/ diphthongs of the 16 men (in gray) and 16 women (in black). The figure, and subsequent statistical analysis, reveals that there is a moderate but significant correlation between onset lowering and strength of diphthongization for the female speakers, r = .481 (p = .030, one-tail) but not for the males, r = .168 (ins.). This finding strengthens the claim that the sound change in progress is predominantly found with female speakers. One might still argue that the acoustic differences between the male and female diphthongs /Ei/ presented so far do not reflect a difference in phonetic vowel quality but are merely due to non-uniform scaling differences between the dimensions of the vocal tracts of men versus women. In order to bear out that the acoustic measures adopted truly reflect differences in auditory vowel quality we have regressed the acoustically defined /Ei/ onset values against a perceptual measure for vowel opening that was reported earlier in Edelman (1999). Edelman reported a perceptual index (based on narrow phonetic transcriptions of diphthongs) for the strength of the Polder Dutch impression that was made by (a random selection of) 13 out of the 32 speakers in the present study. The relationship between acoustic and perceptual strength of the avant-garde quality of these 13 speakers is plotted in figure 6 above. The correlation between acoustic measure and perceptual impression is considerable (r = .742), which clearly indicates that we have not just been measuring the acoustic consequences of differences in the shapes and sizes between male and female vocal organs. 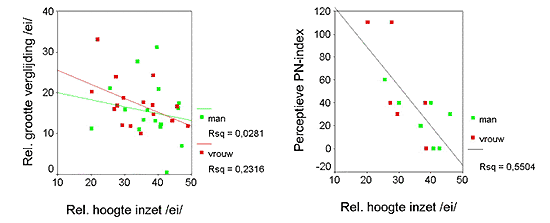
Let us, finally, consider the duration issue of the [Ei] to [a(:)i] change. Figure 6 presents the duration of the target /Ei/ as well as that of the reference point vowels /i/, which is a phonetically short vowel when immediately followed by an obstruent (Nooteboom 1972), and /a/, which is a long vowel. Figure 7 shows that the /Ei/ of both male and female speakers has the same duration as the long, tense reference vowel /a/, and that both /a/ and /Ei/ are some 50 ms longer than the short reference vowel /i/. We computed a speaker-normalized duration measure for /Ei/ by dividing the duration difference between /Ei/ and /i/ into the difference between /a/ and /i/. A paired t-test on the normalized /Ei/ durations revealed no effect of sex of speaker. 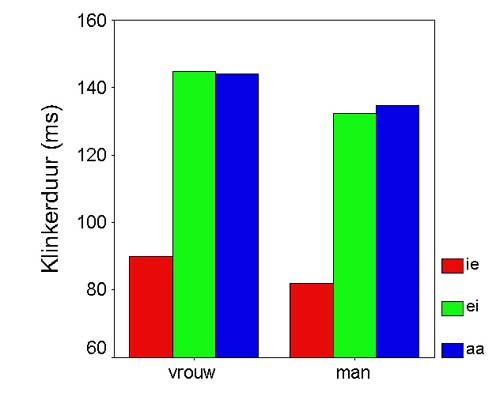 Figure 7. Duration (ms) of short /i/, long /a/ and diphthong /Ei/ for 16 male and 16 female speakers. The duration of /Ei/ is moderately - but significantly - correlated with the size of the spectral change between onset and offset of the diphthong, for both the male and the female speaker groups, r = .626 (p = .005, one-tail) and .531 (p = .017, one-tail), respectively. However, there is no correlation between the onset height of /Ei/ and its duration, for women, r = -.270 (ins.) nor for men, r = -.168 (ins.). We must therefore conclude that the correlation between duration and spectral change is not a part of the sound change in progress; it will be found in any sample of diphthongs. |
||||
|
5. Conclusions and discussion The results that were obtained from the acoustic analysis of the
320 targets diphthongs (10 tokens of /Ei/ for each of 16 male and
16 female speakers) allow us to answer the phonetic issues raised
in the introduction. The phonetic characterization of /Ei/ in the
emerging avant-garde variety of standard Dutch is that it has a
lowered onset. The offset, or end-point of the diphthong, tends
to keep its original vowel height, so that the quality change between
the onset and offset of the diphthong has increased accordingly.
The duration of the new variant of /Ei/ has not changed; as a result
the speed of the spectral change (rate of formant change as visible
in a spectrogram) must have increased as well. |
||||
|
References
|
||||
| Notes 1 No full-scale studies are available on these durations. The differences given here are visible in spectrograms provided by Cohen and Nooteboom (1976: 62) and Rietveld and van Heuven (2001: 153-154). 2 Indeed, whenever Stroop presents illustrations of the new variety on the website or during lectures, it is the diphthong /Ei/ that is used. In fact, the website even invites the public at large to submit a recording of their own production of /Ei/ - rather than some other vowel or diphthong in the language - in order to test whether the particular speaker has already fallen victim to the Polder Dutch sound change. 3 In fact, Stroop produces some examples of male pop-singers who feature the open diphthongs, specifically /Ei/, even today. 4 When formant values are rescaled to Bark, the numerical difference (F1-F2; F2-F1, etc.) is preferred over the ratio. 5 Dutch tense /a/ is quite close to cardinal vowel 4, which phonetically qualifies as a front vowel. Interestingly, tense /a/ patterns with the back vowels in the phonology of Dutch, and is normally given the feature specification [+back], cf. Booij (1995). This analysis does not invalidate the adoption of tense /a/ as the optimal reference vowel for our study. 6 Ms. Lies Kulsdon, assistant producer of Het Blauwe Licht, characterized the guests as "people with considerable cultural payload such as film producers, authors and intellectuals, who are able to uncover the deeper layers of meaning in photographic images and who are not afraid to voice their opinions". |