| Renée van Bezooijen, 'Normen met betrekking
tot het Standaardnederlands' ; gepubliceerd in Taal en Tongval,
themanummer 10 (1997): Standaardisering in Noord en Zuid, blz.30-48
Renée van Bezooijen, Katholieke Universteit van Nijmegen |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Normen met betrekking tot het Standaardnederlands |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Summary 1. Inleiding
De eerste vraag, de consistentie in de oordelen over de mate van
standaardtaligheid, maakt deel uit van onderzoek dat uiteindelijk
tot doel heeft een beschrijving te geven van de kenmerken van het
gesproken Standaardnederlands. Als je wil weten hoe Standaardnederlands
klinkt, zul je eerst van een bepaald spraakfragment moeten vaststellen
dat het Standaardnederlands is. En hoe weet je dat? Op de een of
andere manier zul je die vaststelling moeten baseren op een oordeel.
In eerdere publikaties (Van Rie & Van Bezooijen, 1995; Smakman &
Van Bezooijen, aangeboden) heb ik daarbij een onderscheid gemaakt
tussen impliciete en expliciete beoordeling. De tweede vraag, de consistentie in de oordelen over de mooiheid van het Standaardnederlands in vergelijking met andere variëteiten van het Nederlands, is veel meer gericht op de sociaalculturele inbedding van het Standaardnederlands, op de subjectieve beleving ervan. Oordelen over mooiheid dienen daarbij te worden gezien als een compacte en alledaagse uitdrukking van een positieve of negatieve basishouding ('taalattitude') ten opzichte van de standaardtaal. Het gaat hierbij dus niet om wat als Standaardnederlands wordt gezien, maar HOE er tegen aan wordt gekeken. Deze basishouding is van groot belang voor de positie van het gesproken Standaardnederlands zelf, de invloed die het heeft en de mate waarin het wordt nagestreefd. De basishouding is evenzeer van belang voor de andere variëteiten die in het Nederlandstalige gebied worden gesproken, voor de mate waarin deze als volwaardige en gelijkwaardige communicatiemiddelen worden geaccepteerd en in laatste instantie voor hun overlevingskansen. De vraag naar de aard, consistentie en verklaringen van mooiheidsoordelen komt in paragraaf 3 aan de orde. 2. Oordelen over standaardtaligheid 2.1 Ongetrainde luisteraars over de standaardtaligheid van Nederlandse radiopresentatoren (Smakman & Van Bezooijen, aangeboden) Er werden oordelen verkregen van in totaal 85 Nederlandse luisteraars,
van beiderlei kunne, verschillende leeftijden en uiteenlopende regionale
herkomsten. Hun opleidingsniveau was wat hoger dan gemiddeld. De
oordelen hadden betrekking op spraakfragmenten gesproken door mannelijke
presentatoren in informatieve programma's (reportages en documentaires)
van de nationale Nederlandse radio-omroep (we hadden liever nieuwsuitzendingen
gebruikt, maar die worden helaas niet in hun gesproken vorm gearchiveerd).
Om te kunnen nagaan in hoeverre de oordelen worden beďnvloed door
de veranderingen in het Nederlands zoals dat op de radio wordt gesproken
(vergelijk Van de Velde, 1996), zijn er niet alleen hedendaagse
spraakfragmenten aangeboden maar ook oudere spraakfragmenten. In
het onderzoek werd spraak betrokken van 30 presentatoren. Hun leeftijd
varieerde tussen 29 en 52 jaar. Er waren opnames van vijf presentatoren
uit de vijftiger jaren, vijf uit de zestiger jaren, vijf uit de
zeventiger jaren, vijf uit de tachtiger jaren en tien uit de negentiger
jaren. niet Standaardnederlands 1 2 3 4 5 6 7 8 9 10 Standaardnederlands De waarden op deze schaal kunnen voor het gemak worden vergeleken met rapportcijfers, waarbij 1 als zeer slecht kan worden beschouwd, 2 als slecht, 3 als matig, 4 als onvoldoende, -5 als bijna voldoende, 6 als voldoende, 7 als ruim voldoende, 8 als goed, 9 als zeer goed en 10 als uitmuntend. De spreker die gemiddeld over alle 85 luisteraars het hoogste cijfer kreeg was J.J., een presentator van wie spraak is opgenomen in de negentiger jaren en die is geboren in 1959. Het totaaloordeel bedroeg 7.8, dat wil zeggen net iets minder dan 'goed'. De standaard-deviatie, dat wil zeggen de gemiddelde afwijking van de scores ten opzichte van het algemene gemiddelde, was 1.4. Dit is de kleinste standaard-deviatie van alle sprekers. Aan deze spreker is nooit het cijfer 1, 2 of 3 toegekend en slechts in een enkel geval een 4 of een 5. 66% van de cijfers was een 8 of hoger. Dat de luisteraars het goed eens waren over de toppositie van presentator J.J. blijkt ook uit Tabel 1, waar de resultaten (rang en score) zijn opgesplitst voor verschillende subgroepen van luisteraars. Bijna alle subgroepen (man, vrouw, jong, middelbaar, oud, noord, oost, zuid, west) plaatsen J.J. op de eerste plaats. Tabel 1. Resultaten voor de presentator met de hoogste score voor standaardtaligheid, uitgesplitst naar subgroepen van luisteraars en voor alle luisteraars tezamen
Het bovenstaande had betrekking op standaardtaalspreker nummer 1. Nummer 30, dat wil zeggen de laagst gescoorde spreker, had een gemiddelde score van 5.8, dat wil zeggen net onder 'voldoende'. Het gaat hier om presentator G.W., geboren in 1904 en geregistreerd in de vijftiger jaren. Hij is de oudste spreker in het materiaal. De standaard-deviatie van de scores die aan hem zijn toegekend is 2.3, de grootste van alle standaard-deviaties. Alle cijfers, van 1 tot en met 10, zijn bij de beoordeling door meer dan drie luisteraars omcirkeld. De drie hoogste cijfers (8, 9 and 10) beslaan 24% van de scores, de drie laagste cijfers (1, 2 and 3) 20% van de scores en de vier middelste cijfers (4, 5, 6 en 7) 56% van de scores. Een grote spreiding in de scores dus. Blijkbaar zijn de luisteraars het er meer over eens wie de meest prototypische standaardtaalspreker is dan wie de minst prototypische standaardtaalspreker is. Om een beeld te krijgen van de mate van overeenstemming tussen
de verschillende luisteraargroepen wat betreft de totale rangordening
van alle 30 presentatoren zijn de gemiddelde cijfers voor alle presentatoren
per luisteraargroep paarsgewijs met elkaar vergeleken door middel
van Pearson productmoment correlaties. De uitkomsten zijn te zien
in Tabel 2. Wellicht ten overvloede: bij een correlatiecoëfficiënt,
aangeduid met r, van 1.00 zou er sprake zijn van een compleet identieke
rangordening van de 30 presentatoren door twee luisteraargroepen,
terwijl een r van .00 op een volstrekt gebrek aan overeenkomst duidt.
Als een correlatiecoëfficiënt significant is, betekent
dit dat de gecorreleerde series van gegevens meer overeenkomst vertonen
dan op grond van kans te verwachten is. Vaak echter wordt aan het
al dan niet significant zijn van correlatiecoëfficiënten
niet erg veel waarde gehecht en wordt in plaats daarvan gekeken
naar het percentage gemeenschappelijke variantie van twee gecorreleerde
series van gegevens. Dit percentage, dat uiteraard kan liggen tussen
0% en 100%, wordt verkregen door de correlatiecoëfficiënt
te kwadrateren.
2.2 Getrainde luisteraars over de mate van standaardtaligheid van nietprofessionele Nederlandse sprekers (Van Rie, Van Bezooijen & Vieregge, 1995) De studie van Van Rie, Van Bezooijen en Vieregge (1995) beoogde zicht te krijgen op de relatie tussen globale oordelen over de mate van standaardtaligheid en de uitspraak van afzonderlijke klanken (klinkers en medeklinkers). De spraak die is beoordeeld was afkomstig van 15 spreeksters tussen 20 en 50 jaar die door de tweede auteur waren voorgeselecteerd: alleen vrouwen die in haar ogen niet meer dan een licht regionaal gekleurd accent hadden, zijn in het onderzoek betrokken. De spreeksters waren afkomstig uit verschillende provincies van Nederland, hun opleidingsniveau was hoog. Van iedere spreekster is zowel (semi-)spontane (beschrijvingen van plaatjes) als voorgelezen spraak beoordeeld, met een duur van ongeveer 45 seconden. De beoordeling bestond uit het scoren van de schaal niet Standaardnederlands 1 2 3 4 5 6 7 Standaardnederlands en is uitgevoerd door vijf fonetici werkzaam bij de KU-Nijmegen1. Bij een oordeel lager dan 7, dus als een fragment als niet volledig Standaardnederlands werd beoordeeld, dienden de beoordelaars hun oordeel nader te specificeren door in de uitgeschreven versies van de fragmenten die fonemen te omcirkelen waarvan de realisatie door hen als nietstandaard werd beschouwd. Tevens is het spraakmateriaal door de derde auteur getranscribeerd. De betrouwbaarheid van de oordelen is berekend met behulp van Cronbach's alpha. Deze maat kan grofweg gelijk worden gesteld met een gemiddelde correlatiecoëfficiënt, rekening houdend met het aantal beoordelaars. De betrouwbaarheid is vastgesteld voor de spontane en voorgelezen spraak samen en bedroeg .84. Dit geldt als behoorlijk hoog. Nadere beschouwing van de oordelen bracht het volgende beeld aan het licht. Van de 30 (15 spreeksters x 2 typen spraak) beoordelingsreeksen van vijf oordelen (afkomstig van de vijf beoordelaars) was er sprake van:
De over de beoordelaars gemiddelde scores varieerden tussen 4.8 en 7.0 voor de spontane fragmenten en tussen 4.6 en 7.0 voor de voorgelezen fragmenten. Een gecorreleerde t-toets was niet significant (t=1.03, p=.32), wat wil zeggen dat de hoogte van de scores voor de twee typen spraak gemiddeld niet verschilde: de spreeksters spraken even standaard bij het voorlezen als waneer ze spontaan spraken. Het betreft hier waarschijnlijk personen met weinig variatiebreedte in hun spraak. De correlatie tussen de scores voor de twee typen spraak was hoog, wat wil zeggen dat dezelfde spreeksters die hoog beoordeeld werden met betrekking tot hun spontane spraak ook hoog beoordeeld werden met betrekking tot hun voorgelezen spraak, en andersom. Ook dit bevestigt de stabiliteit van de uitspraak van de betrokken spreeksters. Het bleken vooral de klinker /a/ en de medeklinkers /ˇ/ en /r/ te zijn waarvan de uitspraak tot een verlaging van de beoordelilngsscores leidde. Voor meer details verwijs ik naar de oor-spronkelijke publikatie. 3. Oordelen over mooiheid 3.1 Mooiheidsoordelen voor Standaardnederlands vergeleken met dialecten (Van Bezooijen, 1994, 1995) In het onderzoek naar de relatieve mooiheid van het Standaardnederlands
en Nederlandse dialecten zijn zeven Nederlandse luisteraargroepen
(gemengd mannen en vrouwen) betrokken:
Het stimulusmateriaal bestond uit semi-spontane spraakfragmenten
(beschrijvingen van plaatjes) van ongeveer 20 seconden. De spraak
was afkomstig van telkens vier spreeksters van de volgende vier
variëteiten:
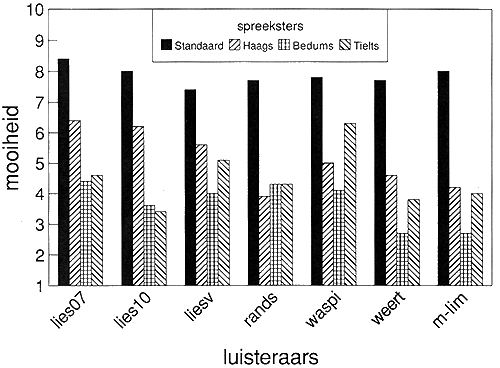
erg lelijk 1 2 3 4 5 6 7 8 9 10 erg mooi De mooiheidsoordelen van de zeven luisteraargroepen zijn afgebeeld in Figuur 1. Het is duidelijk dat het Standaardnederlands in alle gevallen ver uitsteekt boven de drie dialecten, daar is geen enkele uizondering op. Het Standaardnederlands wordt alom het mooist gevonden. Het Haags komt in de meeste gevallen op de tweede plaats en het Bedums en het Tielts daar weer onder. In die gevallen dat er een verschil wordt gemaakt tussen de laatste twee dialecten, wordt het Tielts mooier gevonden dan het Bedums. In Tabel 3 zijn de correlaties tussen de mooiheidsoordelen van de zeven luisteraargroepen voor de 16 spraakfragmenten te zien: ze zijn behoorlijk hoog, op een enkel geval na is er sprake van meer dan de helft gemeenschappelijke variantie. En dit kan oplopen tot boven de 90%. Het is duidelijk dat er in alle onderzochte taalgemeenschappen gemeenschappelijke normen aanwezig zijn over de relatieve mooiheid van verschillende variëteiten van het Nederlands. Daarbij is de positie van het Standaardnederlands het meest uitgesproken en het meest stabiel.
Tabel 3. Correlaties tussen de mooiheidsoordelen van zeven luisteraargroepen. * = p < .01.
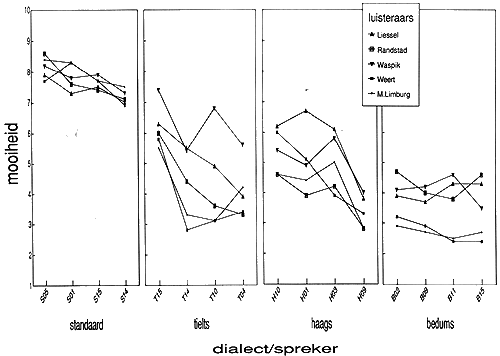
Hoe groot is nu de spreiding in de oordelen voor de vier spreeksters binnen elke variëteit? De oordelen voor de afzonderlijke spreeksters zijn afgebeeld in Figuur 2 (de scores voor de Liesselse kinderen zijn weggelaten omdat ze erg lijken op die van de Liesselse volwassenen). Het verschil tussen het Standaardnederlands en de drie dialecten is opvallend. Voor de Standaardnederlandse spreeksters is de spreiding in mooiheidsoordelen klein, zowel tussen de spreeksters als tussen de luisteraargroepen. In andere woorden: alle luisteraargroepen zijn het met elkaar eens dat alle vier de Standaardnederlandse spreeksters erg mooi klinken. De scores voor het Standaardnederlands zijn enorm compact. Voor het Tielts is er grote spreiding zowel tussen de spreeksters als tussen de luisteraargroepen. Voor het Bedums is er kleine spreiding tussen de spreeksters en grote spreiding tussen de luisteraargroepen, met name tussen de twee Limburgse groepen aan de ene kant, die het Bedums uitzonderlijk lelijk vinden, en de twee Brabantse en de randstedelijke groep aan de andere kant, die in dit opzicht een wat gematigder oordeel hebben. Figuur 2 bevestigt dat vooral de normen met betrekking tot de mooiheid van het Standaardnederlands hecht verankerd zijn in de Nederlandse maatschappij.
Waarom wordt het Standaardnederlands nu zoveel mooier gevonden
dan andere variëteiten van het Nederlands? Deze vraag is niet
alleen van toepassing op de situatie in het Nederlandstalige gebied.
De situatie in het Engelstalige gebied blijkt hetzelfde beeld te
vertonen. Dit blijkt ondermeer uit het onderzoek van Giles (1970)
en Trudgill & Giles (1978). Ook daar wordt het RP (Received Pronunciation,
de standaardvariëteit) systematisch het mooist gevonden. Regionale
variëteiten nemen een middenpositie in en stadsvariëteiten
worden het lelijkst gevonden. In de Engelse literatuur (Giles, Bourhis
& Davies, 1975; Trudgill & Giles, 1978) zijn drie hypotheses opgesteld
om dit patroon van esthetische appreciatie te verklaren, namelijk
de sociale connotatiehypothese ('social connotations hypothesis'),
de opgelegde normhypothese ('imposed norm hypothesis') en de inherente
waardehypothese ('inherent value hypothesis'). We hebben proberen na te gaan in hoeverre de sociale connotatiehypothese, de opgelegde normhypothese en de toegankelijkheidshypothese een verklaring kunnen vormen voor de mooiheidsscores die we in ons onderzoek hebben aangetroffen. De inherente waarde hyothese is moeilijk te toetsen en daarom buiten beschouwing gelaten. Voor de overzichtelijkheid beperk ik mij in de bespreking die volgt tot de mooiheidsscores verkregen met de drie luisteraargroepen uit Liessel. Teneinde de sociale connotatiehypothese te kunnen toetsen hebben
we de Liesselse proefpersonen niet alleen gevraagd de 16 spraakfragmenten
te scoren op mooiheid, maar hebben we hun ook (in een andere ronde,
met een andere stimulusvolgorde) gevraagd zich een beeld te vormen
van het beroep en de woonsituatie van de spreeksters van de fragmenten.
Wat betreft het beroep moesten de luisteraars kiezen uit negen tekeningen,
waarop de volgende beroepen stonden afgebeeld: (vrouwelijke) professor,
onderwijzeres, secretaresse, verpleegster, boerin, verkoopster,
caissičre, huisvrouw en fabriekarbeidster (deze beroepen zijn hier,
op grond van de beroepenklapper van het Insituut voor Toegepaste
Sociologie (Westerlaak, Kropman, & Colaris, 1975) geordend van hoge
naar lage status). Wat betreft de woonsituatie moesten de luisteraars
kiezen uit vier tekeningen waarop stereotiepe voorstellingen van
de woonomstandigheden van de vier sprekergroepen waren afgebeeld:
een rustiek dorpje met boerderijen en een kerktoren (Bedum), een
oud stadje met een caféterras en gevelhuizen (Tielt), een armoedige,
vervallen stadswijk (Den Haag) en een luxueuze villawijk (Standaardnederlands). Om de (uitgebreide vorm van de) opgelegde normhypothese te kunnen toetsen waren er gegevens nodig over de waargenomen afstanden van de vier variëteiten tot het prototypische Standaardnederlands. En om de toegankelijkheidshypothese te kunnen toetsen waren er gegevens nodig over b.v. de verstaanbaarheid. Deze gegevens zijn verkregen door de 16 spraakfragmenten door 25 studenten van de KU-Nijmegen (voor het merendeel afkomstig uit de provincies Noord-Brabant en Limburg) te laten scoren op de schalen: geheel niet standaard 1 2 3 4 5 6 7 8 9 10 geheel standaard De gemiddelde standaard- en verstaanbaarheidsscores voor de vier variëteiten zijn te vinden in Tabel 4. De gegevens spreken voor zich: aan de fragmenten die vooraf door fonetici als zeer Standaardnederlands zijn beoordeeld, worden ook door de studenten zeer hoge cijfers voor standaardtaligheid toegekend (rapportcijfer 'zeer goed'). Het Haags neemt een middenpositie in ('bijna voldoende'). En het Bedums en Tielts krijgen beide zeer lage cijfers ('slecht'-). De rangordening voor verstaanbaaarheid is vrijwel hetzelfde als die voor standaardtaligheid. Het grootste verschil is de positie van het Haags, dat relatief gesproken verstaanbaarder is dan het standaardtalig is. Tabel 4. Gemiddelde scores voor standaardtaligheid en verstaanbaarheid voor vier variëteiten
De correlaties tussen de mooiheidsscores van de drie Liesselse luisteraargroepen en de oordelen op de standaard- en verstaanbaarheidsschaal door de Nijmeegse studenten zijn te vinden in Tabel 5. Ook is hierin de onderlinge correlatie van standaardtaligheid en verstaanbaarheid gegeven. Deze laatste correlatie blijkt zeer hoog te zijn, wat wil zeggen dat de rangordening van de 16 spreeksters op de twee schalen vrijwel identiek is. Ook de andere correlaties in de tabel zijn opvallend hoog, alle boven de .80. Dit betekent dat toegekende mooiheid zowel sterk samenhangt met toegekende standaardtaligheid als met toegekende verstaanbaarheid. De gegevens in Tabel 5 geven dus geen uitsluitsel over de relatieve plausibiliteit van de opgelegde normhypothese en de toegankelijkheidshypothese: zowel de relatieve standaardtaligheid als de relatieve verstaanbaarheid kan hebben geleid tot de relatieve mooiheid van de beoordeelde fragmenten. Hieronder zal een ander onderzoek worden beschreven, waarin vrijwel geen variatie in verstaanbaarheid was maar wel variatie in standaardtaligheid. Ook in dit onderzoek is luisteraars om mooiheidsoordelen gevraagd. Tabel 5. Productmoment correlaties tussen de mooiheidsscores van drie Liesselse luisteraargroepen en scores voor standaardtaligheid door studenten van de KU-Nijmegen
3.2 Mooiheidsoordelen voor de spraak van radiopresentatoren (Smakman & Van Bezooijen, aangeboden) Dezelfde 30 fragmenten van radiopresentatoren uit de jaren vijftig
tot negentig die door een gevarieerde groep van 85 luisteraars zijn
beoordeeld met betrekking tot de mate van standaardtaligheid (zie
paragraaf 2.1) zijn ook beoordeeld op mooiheid. Het zij opgemerkt
dat het in dit geval spraakfragmenten betrof die alleen op fonetisch/fonologisch
niveau van elkaar verschilden in de mate van standaardtaligheid.
Bovendien ging het hier niet zozeer om regionaal gebonden verschillen
in uitspraak, maar veeleer om tijdgebonden uitspraakverschillen
(aan de luisteraars is overigens niets verteld over de aard van
variatie tussen de sprekers). In deze twee opzichten is er dus een
duidelijk verschil met de spraakfragmenten waarvan de esthetische
appreciatie in de voorgaande paragraaf is beschreven, Vooralsnog houden wij het erop dat de structuur die wij in de mooiheidsbeoordeling van variëteiten van het Nederlands hebben aangetroffen voor een groot deel verklaard kan worden vanuit de opgelegde normhypothese. Dat wil zeggen dat in de Nederlandse samenleving sterk de nadruk wordt gelegd op de superioriteit van het Standaardnederlands. Deze attitude uit zich heel nadrukkelijk in het onderwijs, waar afwijkingen van de standaard (nog steeds) genadeloos worden afgestraft. Maar je merkt het ook sterk in de media, waar b.v. in telefoonspelletjes ridiculiserend en in mijn ogen beledigend op accenten wordt gereageerd. En ten slotte blijkt het ook uit allerlei berichten over het afwijzen van mensen voor bepaalde beroepen op grond van hun accent. Daarbij wordt als argument gebrek aan verstaanbaarheid gebruikt, maar het is nooit experimenteel aangetoond dat (in de prakijk zeer lichte) accenten van het Nederlands voor de gemiddelde Nederlander minder verstaanbaar zouden zijn dan het Standaardnederlands. Verstaanbaarheid heeft, natuurlijk binnen bepaalde perken, vooral met precizie van articulatie te maken. In feite gaat het, zeker bij lichte accenten, om irrationeel gemotiveerde negatieve taalattitudes.
Article published on the WWW: October 1999 j.stroop@hum.uva.nl |